
Query-Dependent Video Representation for Moment Retrieval and Highlight Detection (CVPR23)
WonJun Moon*1 SangEek Hyun*1 SangUk Park2 Dongchan Park2 Jae-Pil Heo1
Sungkyunkwan University1 Pyler2
* : Equal Contribution
Abstract
Recently, video moment retrieval and highlight detection (MR/HD) are being spotlighted as the demand for video understanding is drastically increased. The key objective of MR/HD is to localize the moment and estimate clip-wise accordance level, i.e., saliency score, to the given text query. Although the recent transformer-based models brought some advances, we found that these methods do not fully exploit the information of a given query. For example, the relevance between text query and video contents is sometimes neglected when predicting the moment and its saliency. To tackle this issue, we introduce Query-Dependent DETR (QD-DETR), a detection transformer tailored for MR/HD. As we observe the insignificant role of a given query in transformer architectures, our encoding module starts with cross-attention layers to explicitly inject the context of text query into video representation. Then, to enhance the model’s capability of exploiting the query information, we manipulate the video-query pairs to produce irrelevant pairs. Such negative (irrelevant) video-query pairs are trained to yield low saliency scores, which in turn, encourages the model to estimate precise accordance between query-video pairs. Lastly, we present an input-adaptive saliency predictor which adaptively defines the criterion of saliency scores for the given video-query pairs. Our extensive studies verify the importance of building the query-dependent representation for MR/HD. Specifically, QD-DETR outperforms state-of-the-art methods on QVHighlights, TVSum, and Charades-STA datasets.
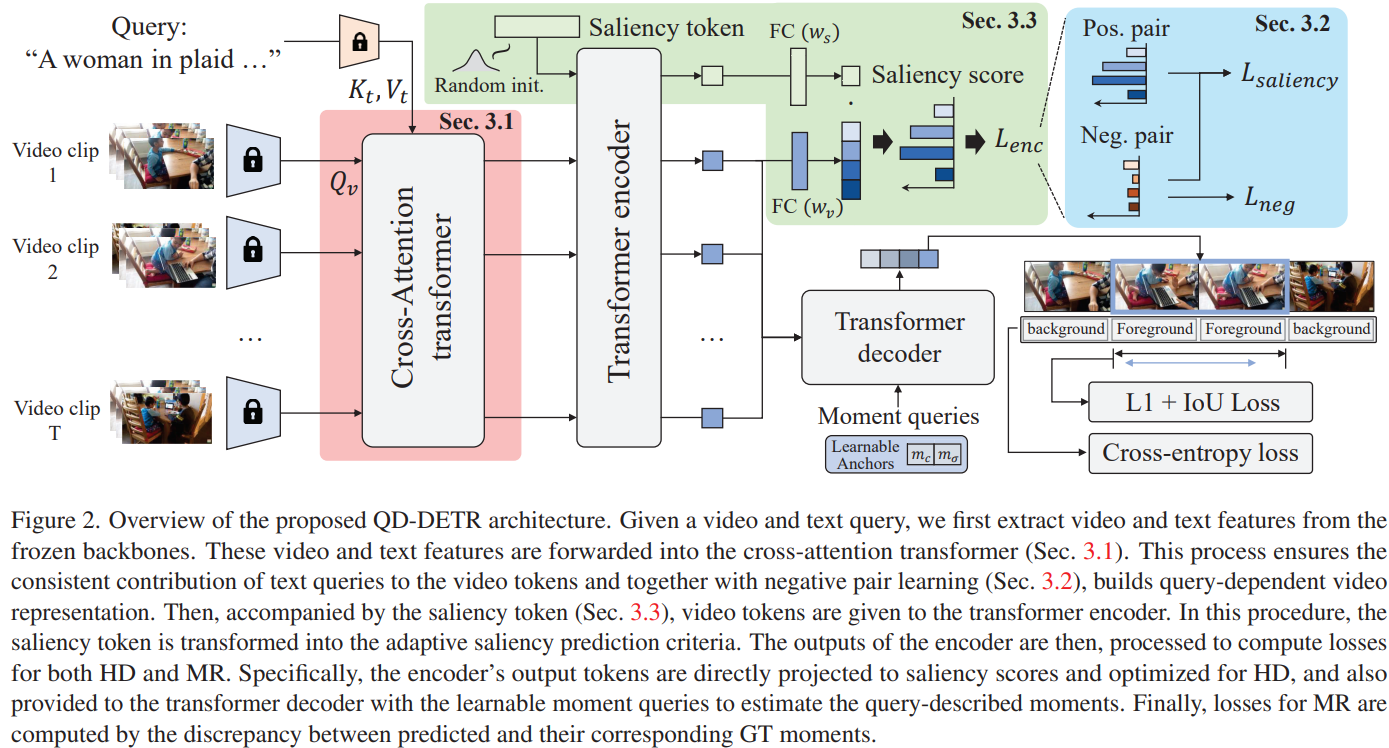
Method
Cross-Attentive Transformer Encoder
- Self-Attention is not enough to attention different modalities since continuous frames are visually too similar and there is a modality gap.
- Cross-Attention explicitly ensures that textual info is embedded in video representation.
- Fusing multi-modal features using a cross-attention layer enables the use of temporal-conditional query which is a temporal version of DAB-DETR.
Learning from Negative Relationship
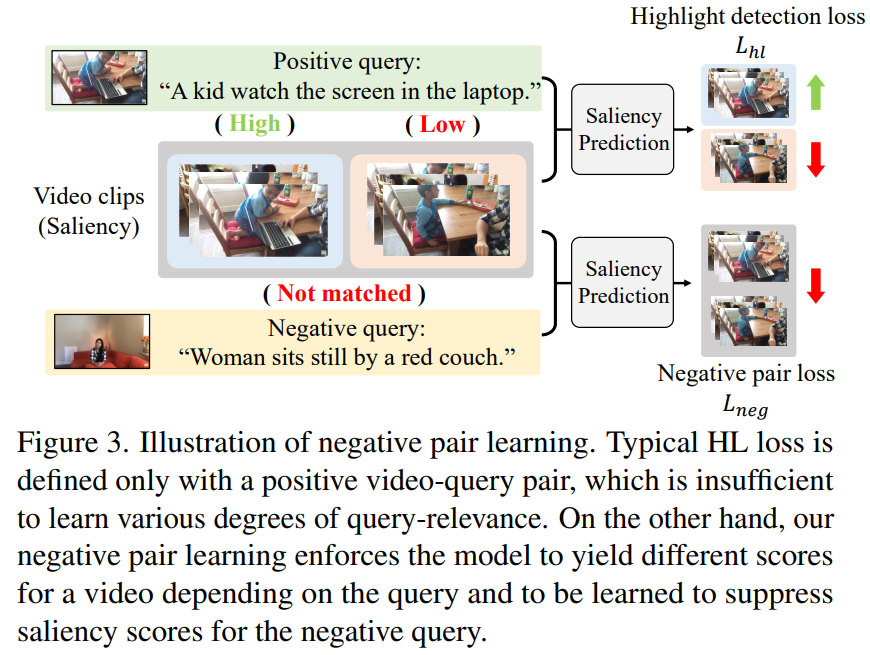
- Negative-pair learning ensures the learning of general relationship between video and text.
- We expect tthe high involvement of text info since video-text similarity gets more distinguishable.
Input-Adaptive Saliency Predictor
- Naive use of single MLP as a saliency predictor cannot cover diverse nature of video-text pairs.
- Instead, we define saliency token that is adaptively transformed into input-dependent saliency token via attention layers.
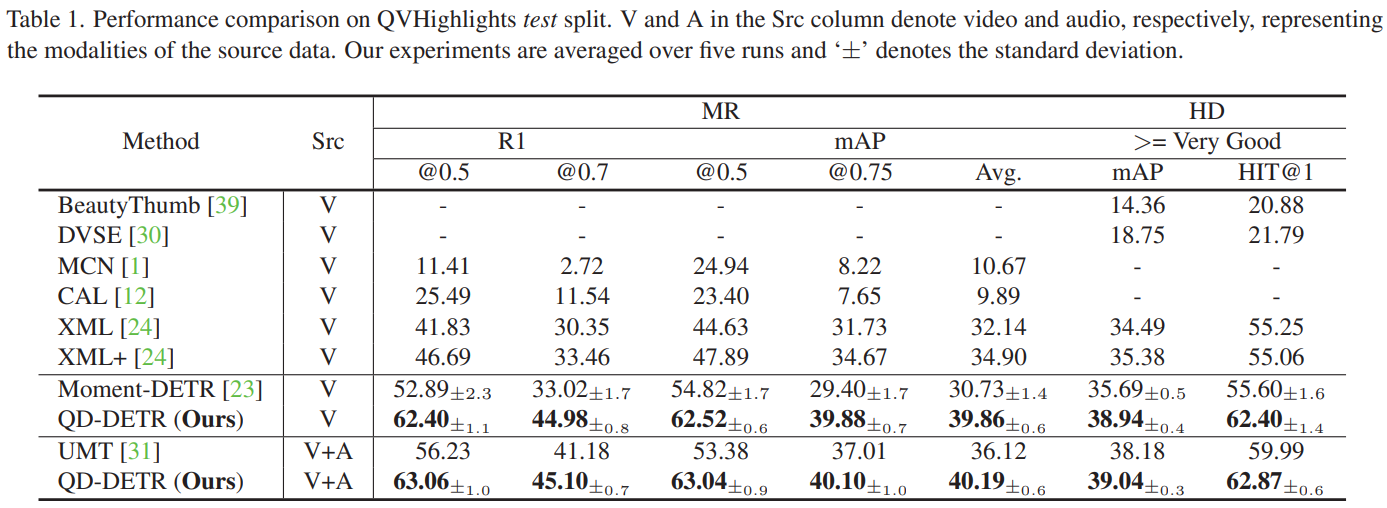
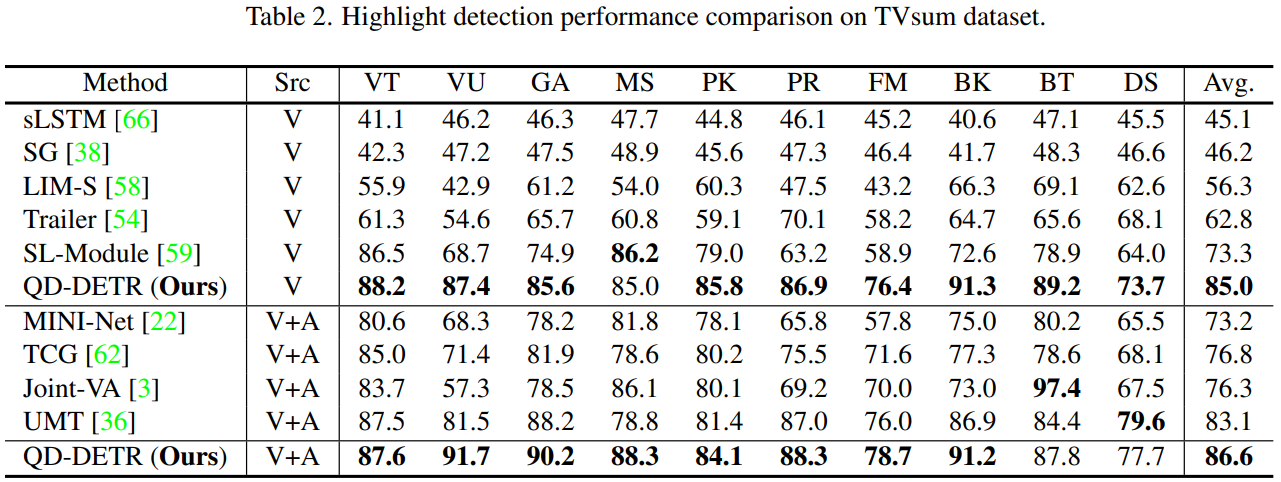
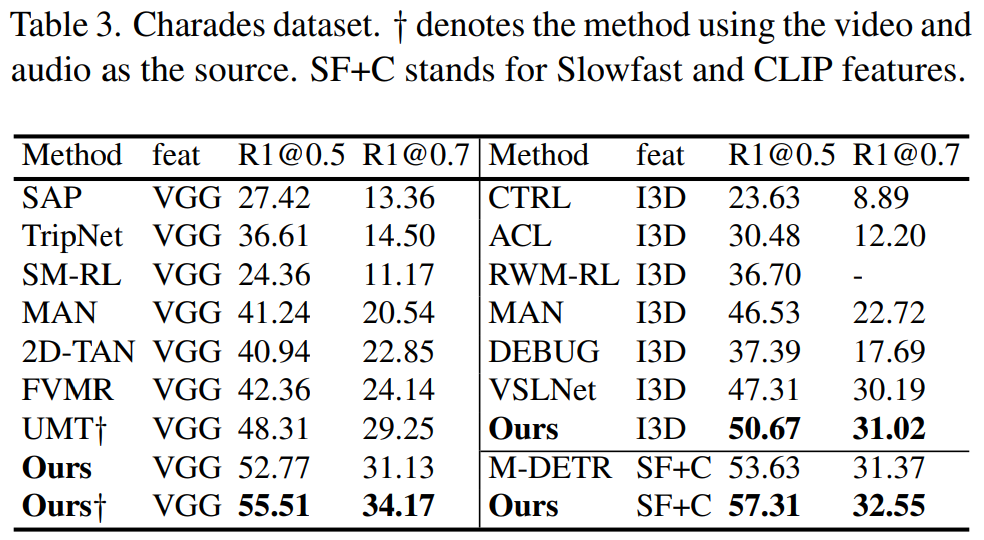
Experiment
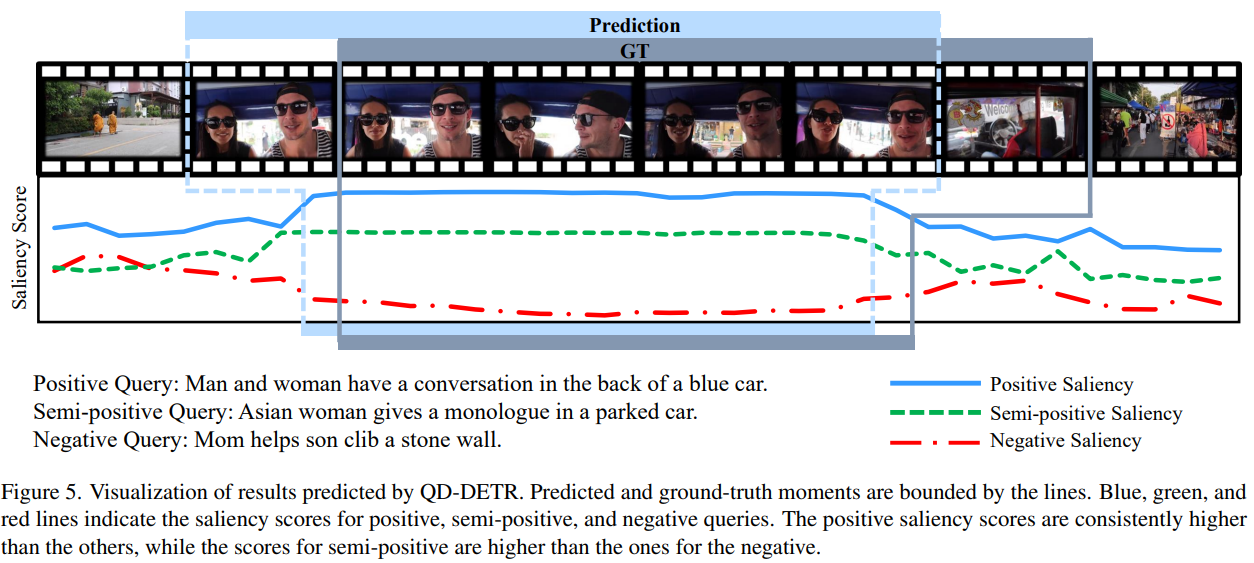
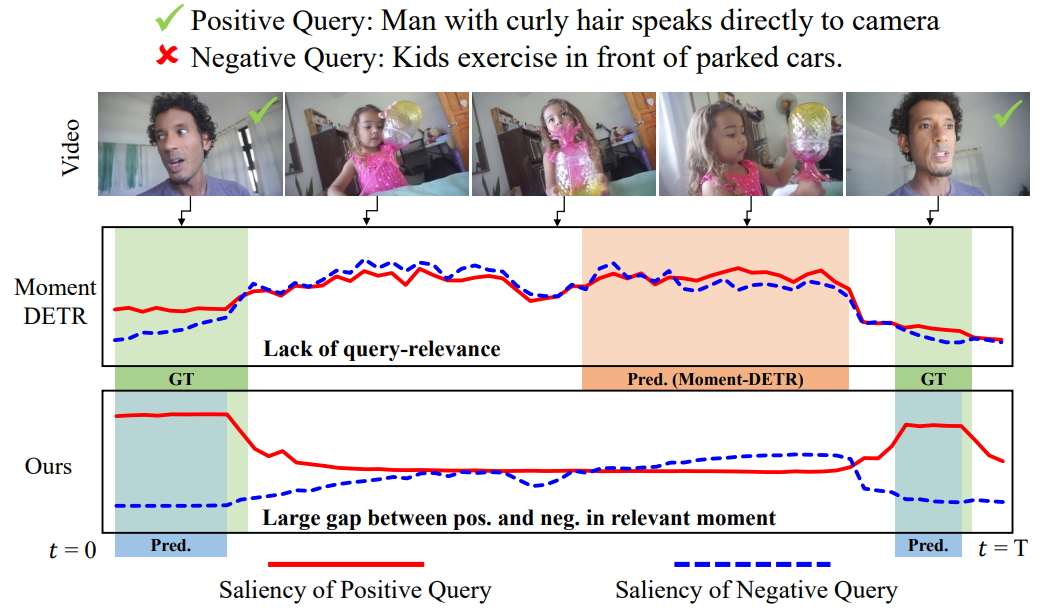
Bibtex
@inproceedings{moon2023query,
title={Query-dependent video representation for moment retrieval and highlight detection},
author={Moon, WonJun and Hyun, Sangeek and Park, SangUk and Park, Dongchan and Heo, Jae-Pil},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={23023--23033},
year={2023}
}