
Minority-Oriented Vicinity Expansion with Attentive Aggregation for Video Long-Tailed Recognition (AAAI23)
WonJun Moon Hyun Seok Seong Jae-Pil Heo
Sungkyunkwan University
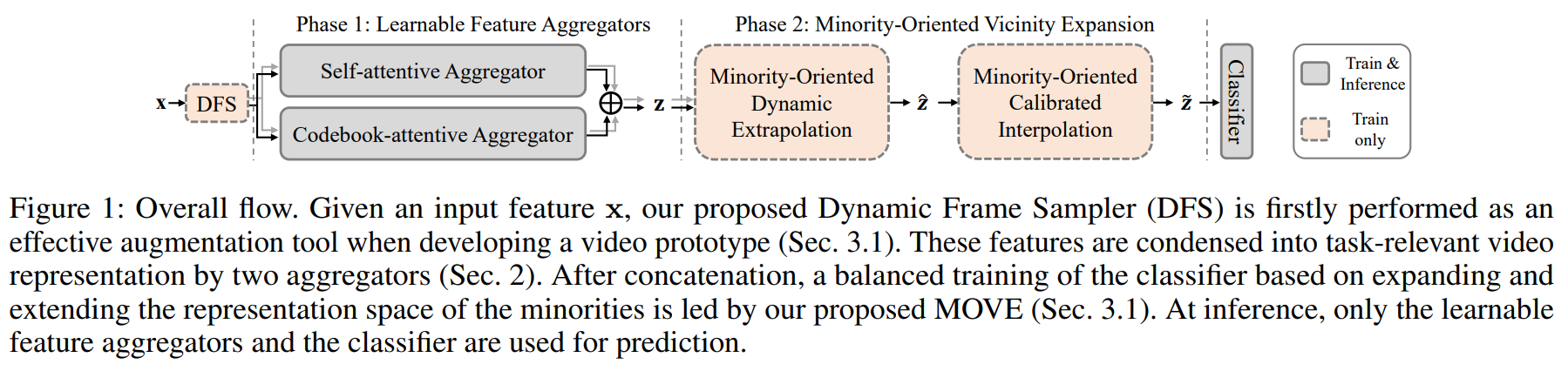
Abstract
A dramatic increase in real-world video volume with extremely diverse and emerging topics naturally forms a long-tailed video distribution in terms of their categories, and it spotlights the need for Video Long-Tailed Recognition (VLTR). In this work, we summarize the challenges in VLTR and explore how to overcome them. The challenges are: (1) it is impractical to re-train the whole model for high-quality features, (2) acquiring frame-wise labels requires extensive cost, and (3) long-tailed data triggers biased training. Yet, most existing works for VLTR unavoidably utilize image-level features extracted from pretrained models which are task-irrelevant, and learn by video-level labels. Therefore, to deal with such (1) task-irrelevant features and (2) video-level labels, we introduce two complementary learnable feature aggregators. Learnable layers in each aggregator are to produce task-relevant representations, and each aggregator is to assemble the snippet-wise knowledge into a video representative. Then, we propose Minority-Oriented Vicinity Expansion (MOVE) that explicitly leverages the class frequency into approximating the vicinity distributions to alleviate (3) biased training. By combining these solutions, our approach achieves state-of-the-art results on large-scale VideoLT and synthetically induced Imbalanced-MiniKinetics200. With VideoLT features from ResNet-50, it attains 18% and 58% relative improvements on head and tail classes over the previous state-of-the-art method, respectively.
Method
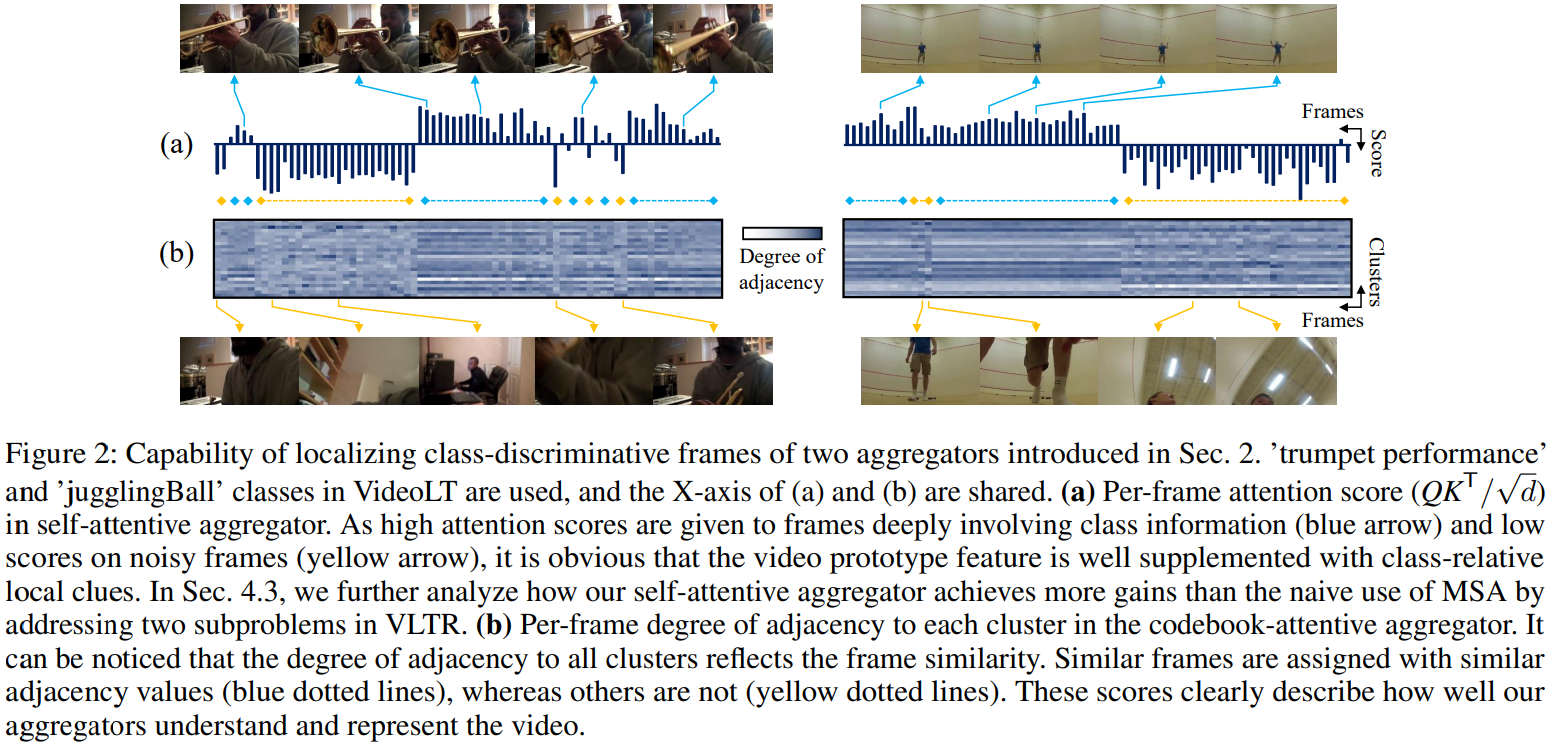
Aggregators
- Weak supervision problem (one class label per multiple-frame video) cannot be handled as noisy-label problem because of biased training in long-tailed circumstances.
- Pretrained features need to be finetuned for the downstream task.
- Thus, we use aggregators to aggregate frames into a video prototype. (2 aggregators to minimize the information loss while aggregating the frame-level features.)
Minority Oriented Vicinity Expansion
- Long-tailed distribution causes biased training.
- To expand and extend the boundaries of the minority classes, we use dynamic extrapolation and calibrated interpolation.
- Dynamic extrapolation is implemented between two prototypes of the same instance to prevent generating outliers.
- And to only diversify the only tail classes, we propose dynamic frame sampler.
- After, calibrated interpolation is implemented to extend the boundaries of the tail classes.


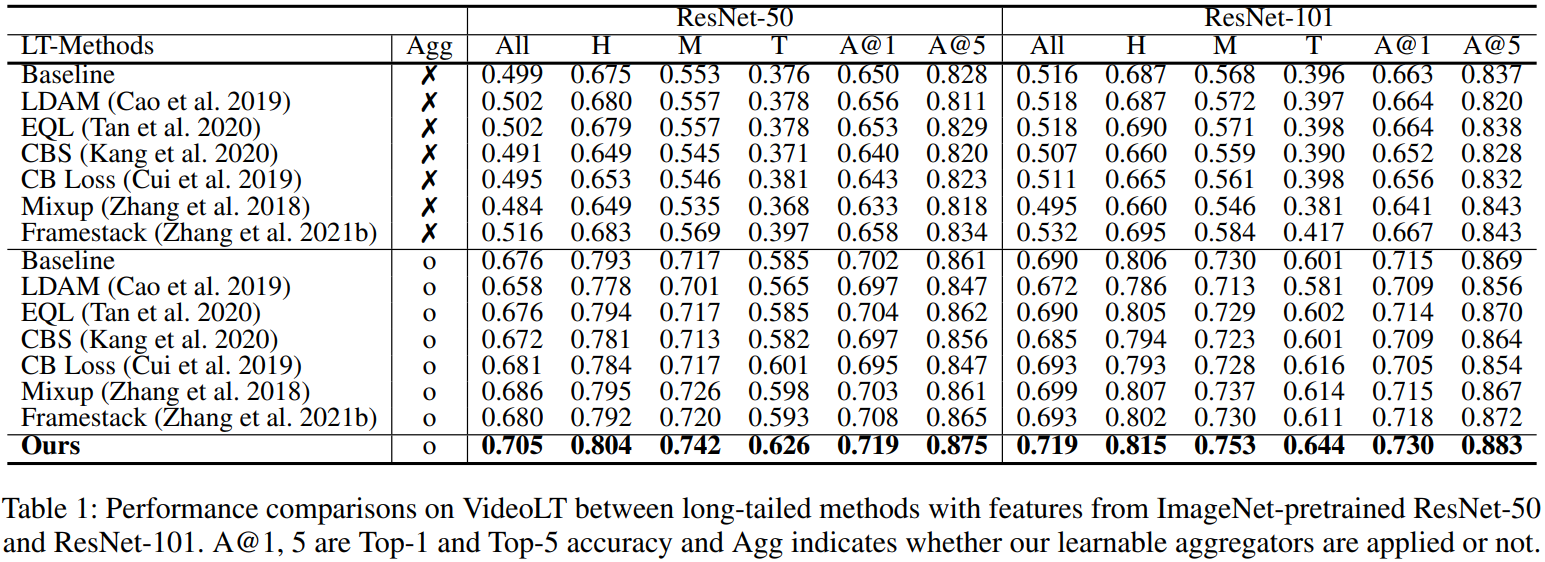
Experiment
- In addition to VideoLT, the large scale video long-tailed dataset, we also introduce and run experiments on Imbalanced-MiniKinetics200.
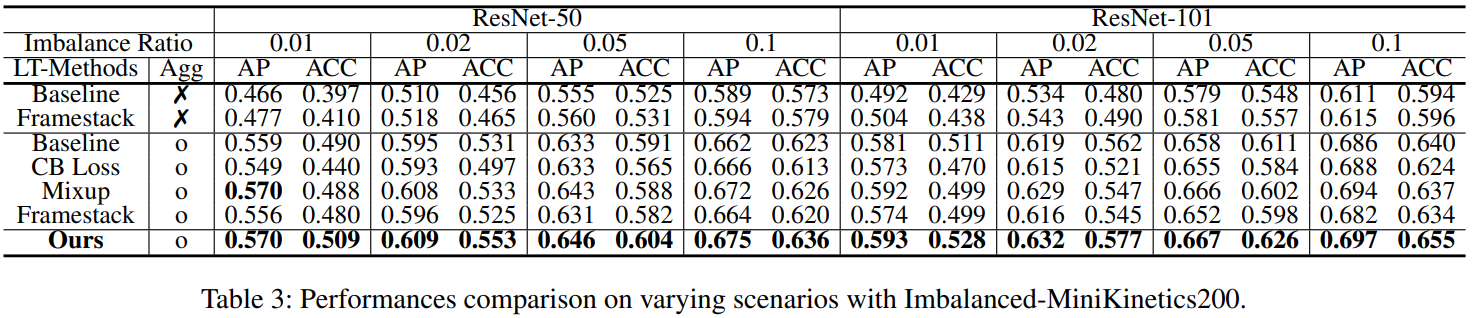
Dataset (Imbalanced-MiniKinetics200)
- Imbalanced-MiniKinetics200 consists of 200 classes which are extracted from Kinetics-400.
- Features and original files are available through the google drive link. Imb.MiniKinetics200 Dataset
Bibtex
@inproceedings{moon2023minority,
title={Minority-Oriented Vicinity Expansion with Attentive Aggregation for Video Long-Tailed Recognition},
author={Moon, WonJun and Seong, Hyun Seok and Heo, Jae-Pil},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={37},
number={2},
pages={1931--1939},
year={2023}
}